【竞赛分享】从高分辨率数据中获取辅助信息:一种电力负荷数据的增强超分辨率重构方案
从高分辨率数据中获取辅助信息:一种电力负荷数据的增强超分辨率重构方案
一、问题介绍
智能电网是将现代社会中原有的输、配电基础设施与通信网络和数据管理系统高度集成 而形成的先进的测量基础设施,通过记录负荷分布在电力输送系统中发挥着至关重要的作用。智能电网中的大数据分析大大提高了电力服务行业的运行效率、可靠性和可持续性,在负荷分析、负荷预测和负荷管理等关键应用领域中准确、高频和可靠的高频电力数据是必不可少的。然而,收集高频数据在实践中是相当困难的,高频数据需要更高的数据通信与存储成本,此外,电网中已经存在大量的低频电表,更换为高频电表的成本是昂贵的。因此,研究获取高时间分辨率数据的数据重构机制具有重要意义。
二、相关工作
传统的超分辨方法可以分成两大类,插值方法和正则化方法,但是传统的方法通常会丢失细节信息和周期特征,导致重构的时序数据过于平滑。随着深度学习的发展,深度学习已经应用于超分辨率重构领域。其中,SRCNN是最早用于超分辨重建问题的模型,之后研究人员们提出许多基于卷积的模型,尤其是在图像超分辨领域。针对电力数据的时序超分辨问题,有工作提出基于卷积的从低频数据恢复高频数据的深度学习方法,并取得显著的效果。然而卷积方法依赖于小区域上下文,具有一定局限性。为了解决这一问题,有工作提出了基于GAN的超分辨重构方法,通过将数据转化成图像,包含更多的上下文信息。虽然数据图像比一维数据可以包含更多信息,但是上下文依赖长度仍然有限,而且数据图像只能重构平方倍的数据。
三、文章动机
现有的解决方法专注于短时上下文信息的超分辨重构。对于时间序列,学习周期性规律和更长时间依赖有助于更好的进行超分辨重构。此外,低频负荷数据和重构的高频负荷数据并不完全对应。
为了解决上述问题,本文提出一个基于transformer的辅助学习的增强超分辨重构框架。我们以数据最长的周期T为一个时间长度,构造一个标准数据库提供辅助信息,该数据库包含长度为T的低频标准数据和对应的高频数据。周期内的数据变化具有相似性,根据这一特性,我们将要求的低分辨率数据与标准库的低分辨率数据进行比较注意,将标准库对应的高分辨率数据信息提供给重构的的高分辨率数据。
我们提出的方法不仅能利用transformer充分学习数据的长时依赖性,而且通过标准数据库提供的先验知识,从高分辨率数据中获得周期变化、低频映射高频的辅助信息,指导高频数据的重构。
四、算法框架
在下方我们展示了我们方法的整体架构及每个模块的作用。该框架主要有四个模块组成,分别是数据预处理、特征提取,注意和补充以及数据重构。
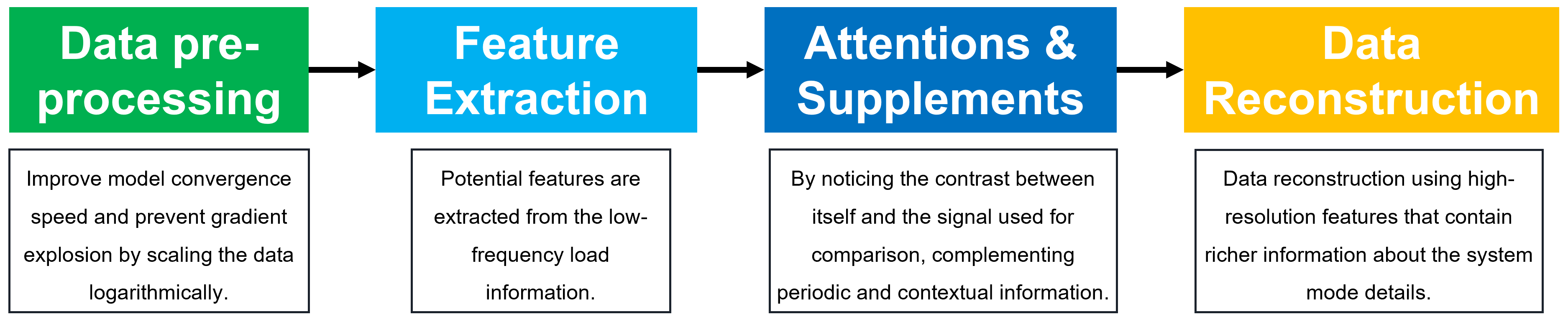
整体架构
数据预处理:负荷数据及其变化过大,通过将数据进行对数缩放,将数据及其变化幅度缩小,提升模型收敛速度,防止梯度爆炸。
特征提取:从低频负荷信息中提取潜在的信息特征。
信息注意和补充:对潜在特征进行注意,通过对自身与标准知识库的注意补充周期性信息和上下文信息,学习低频与高频对应关系。
数据重构:使用包含更多系统模式细节的丰富信息的高分辨率特征进行数据重构。
4.1 数据预处理
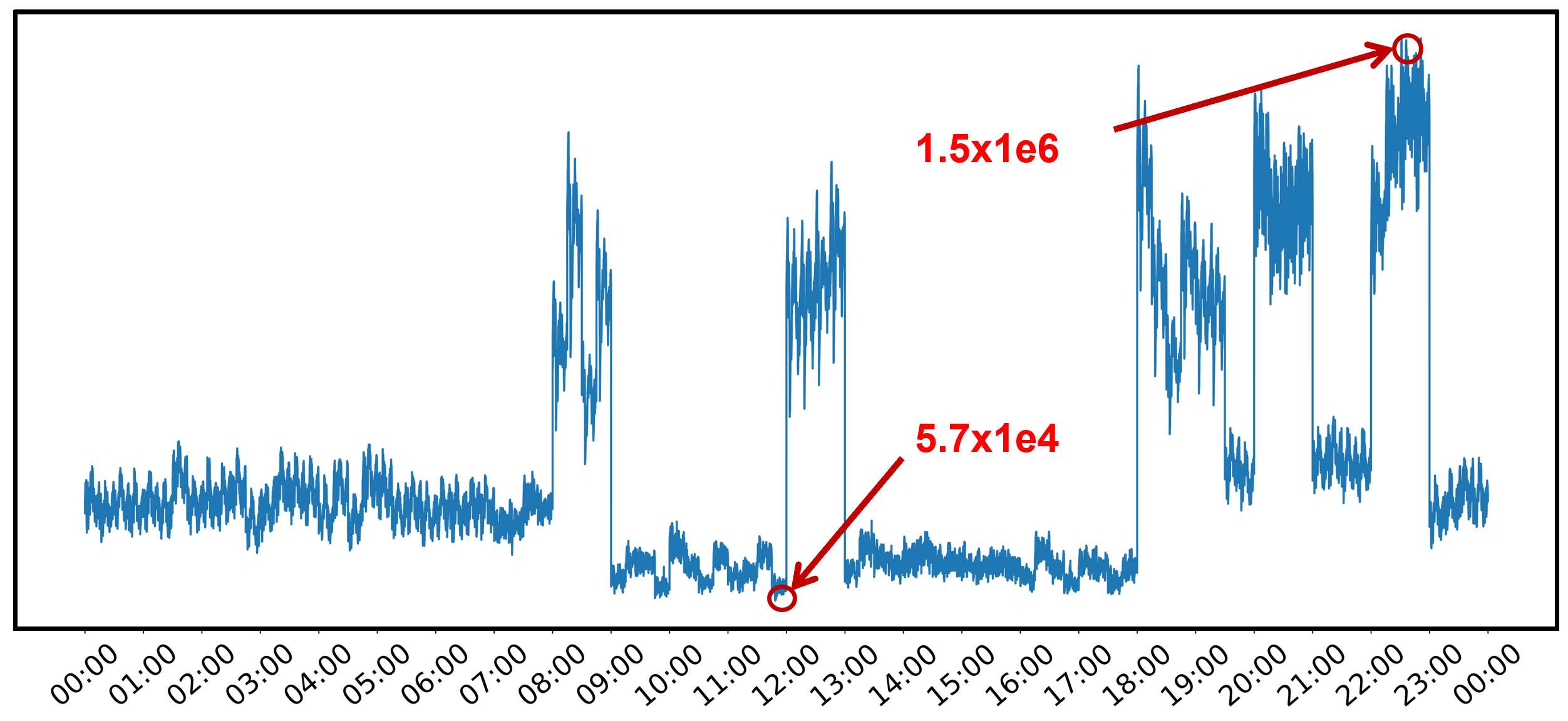
随机选取一天的负荷数据
我们对数据分析发现,数据有两个特点,第一个特点就是范围大。电力负荷数据具有非常大的动态变化范围。因此我们采用对数缩放法。第二个问题是高峰期和非高峰期存在不同的变化范围。高峰期在百万级别,非高峰期只有数十万。不同的范围使得高峰期的负荷经过对数处理后,损失了变化幅度。因此在将高峰期数据输入模型之前对原始数据减去部分数值(使其变化范围不和非高峰期重叠)后再做对数处理,以此来弥补变化幅度损失。
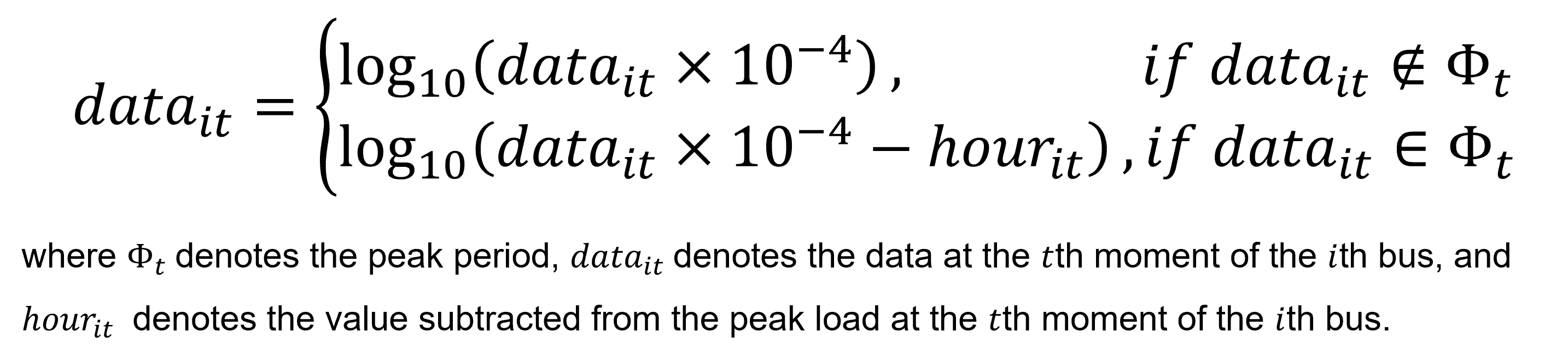
数据预处理公式
4.2 特征提取
我们特征提取模块的架构图如图所示。首先可以看到我们的输入,是要求的低频数据x,还有作为先验知识的低高频数据standard1hz、standard10hz,因为低高频数据并不是直接对应,所以对低高频数据,要用不同的特征提取。同时我们要保证低频数据进行相同的特征提取,保证特征的稳定性。
完全不同的特征提取块会增加大量的参数,并且导致过拟合。我们采用了一种折中的办法,设计部分不同的特征提取层。经过我们的实验表明,只需要在开头的这层用不一样的卷积提取浅层特征就可以实现。就是图中标黄色的部分。在模块中,高频数据特征进行了下采样处理,使得长度对齐。
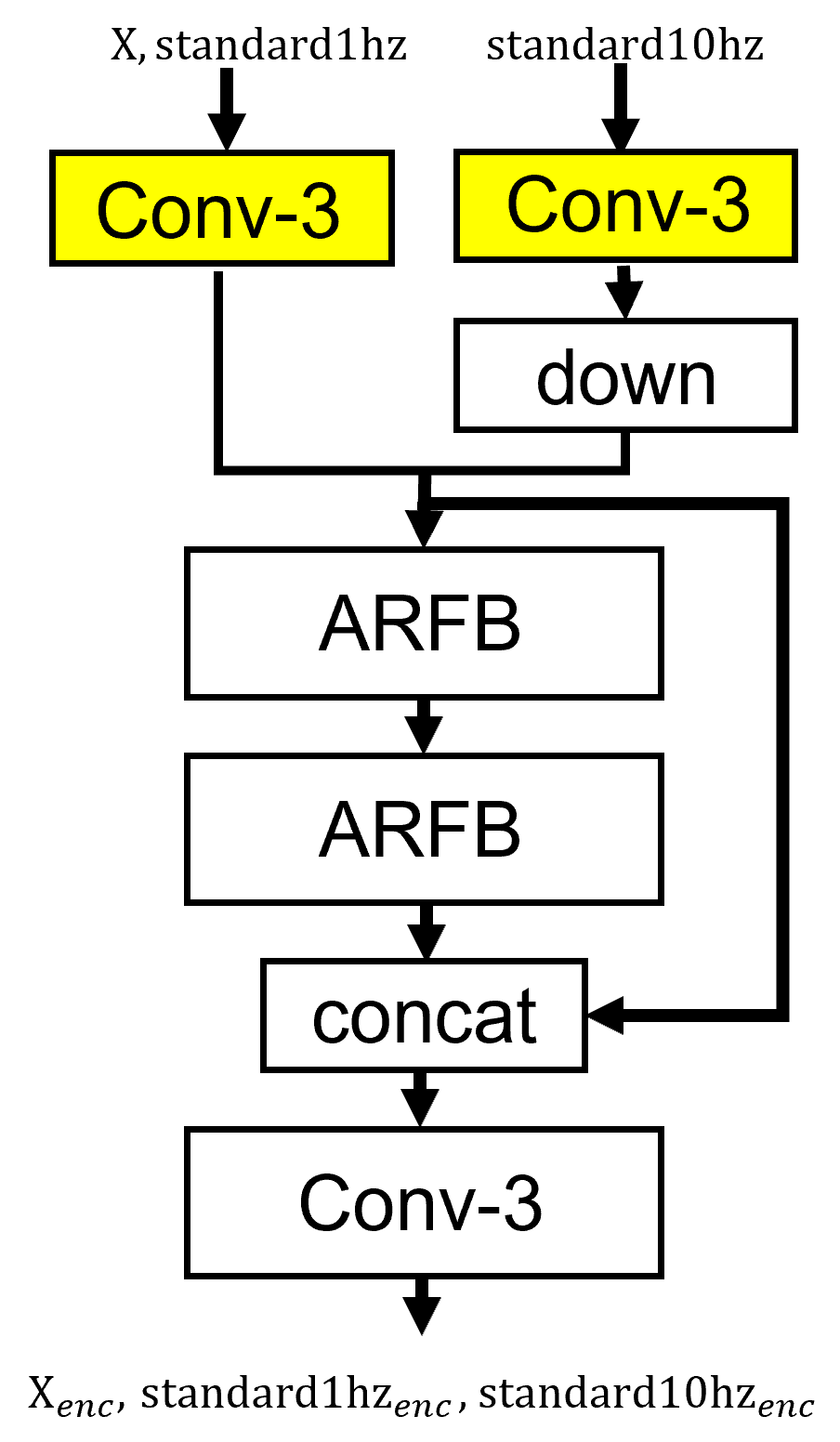
特征提取
其中ARFB是自适应残差特征块,出自论文《Transformer for single image super-resolution》。它有三个特点,第一个是残差结构,迫使网络学习丢失的信息。第二个是它可以动态调整残差路径和身份路径的重要性,改善梯度的流动性,并自动调整残差特征映射的内容。第三个是用了通道注意,学习特征之间的耦合。
4.3 注意和补充
在注意补充模块,我们用transformer注意机制。transformer是一个有力的注意机器。由于我们可以利用数据的上下文信息,因此我们只取transformer的编码器部分。
transformer示意图
在这里简要介绍一下transformer,它由高效多头注意(EMHA)和前馈网络组成,注意机制如左图所示。EMHA由多个缩放点积注意块拼接而成。缩放点积注意的原理如下图,它是通过将特征变量乘以三个矩阵,得到三个变量矩阵Q、K和V。Q就是询问矩阵,K是键矩阵,通过询问-键确定点与点之间的相似度,得到注意矩阵,然后乘以值矩阵。
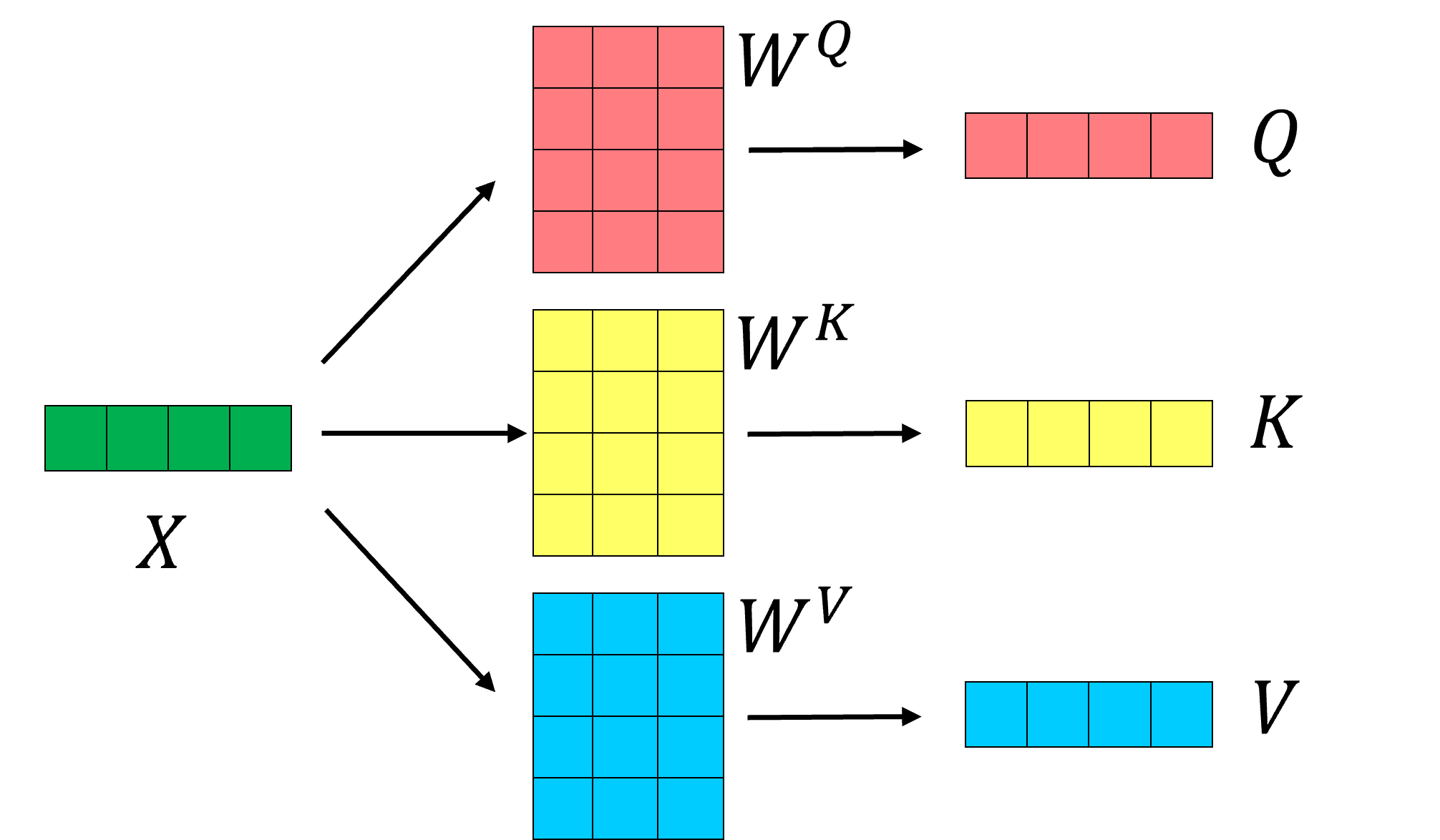
缩放点积注意
Q就是询问矩阵,K是键矩阵,通过询问-键确定点与点之间的相似度,得到注意矩阵,然后乘以值矩阵V。
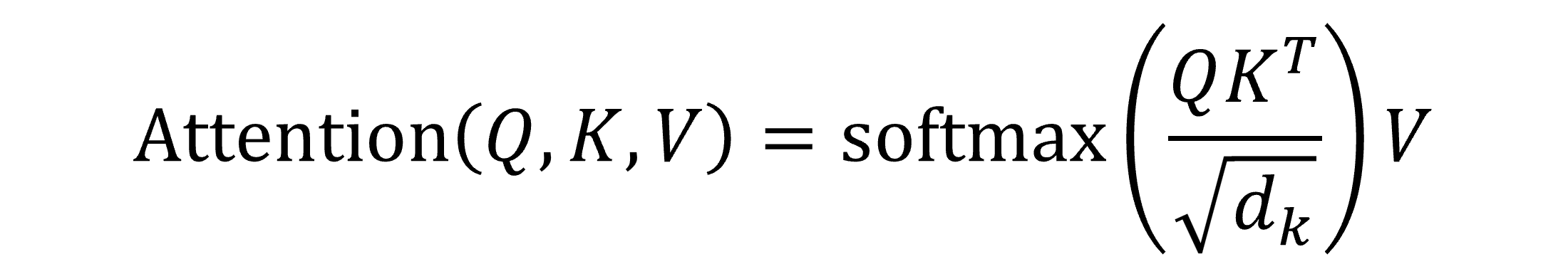
注意计算
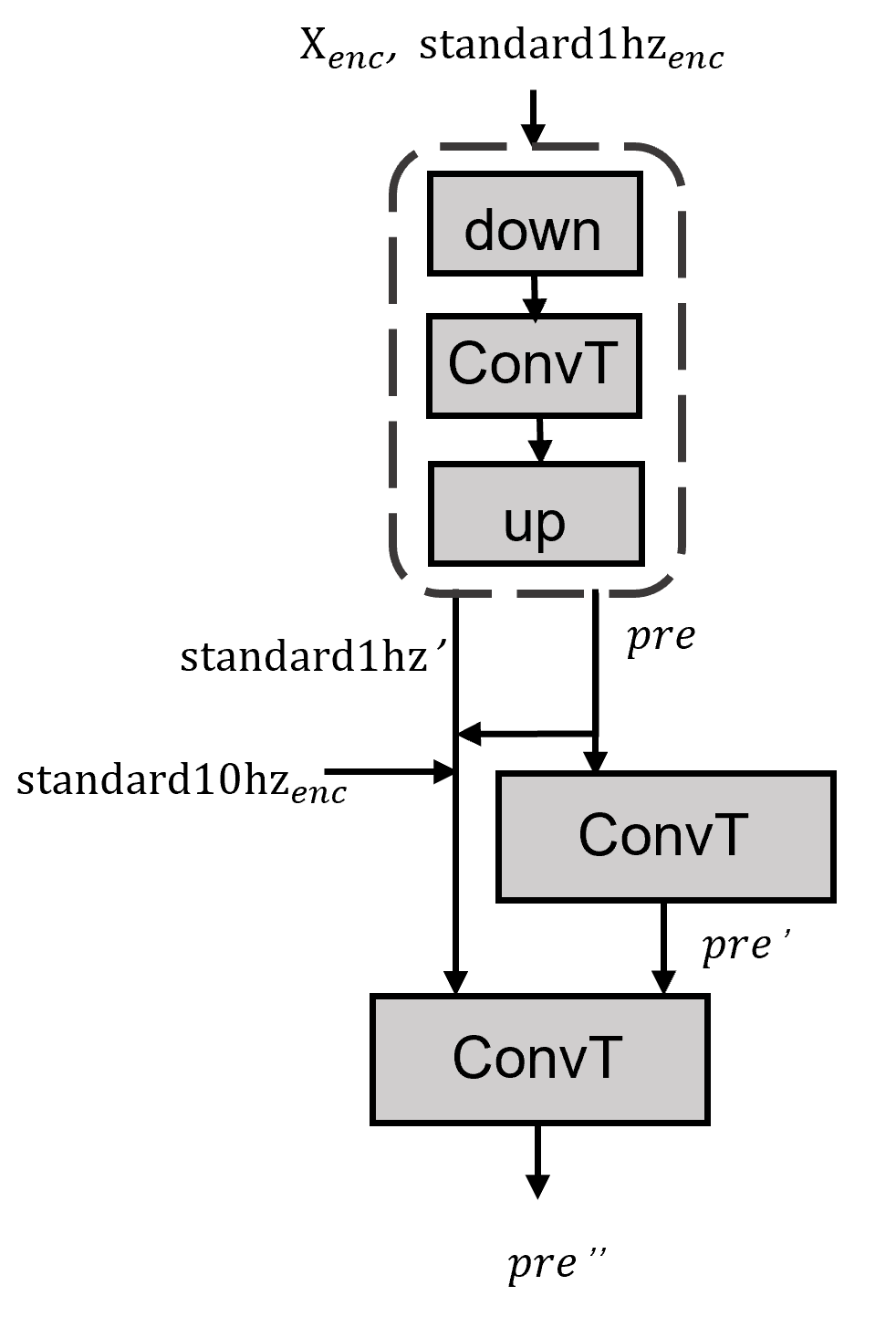
在注意补充模块里面我们用了三层的transformer,并把每一层的Q、K和V列在表格中。我们在这里用ConvT表示我们用的卷积transformer,它是transformer的变体,出自《Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting》,它的特殊之处就是在于将点积换成了卷积。
注意和补充
第一层注意我们使用了一个下采样再上采样的结构,以减少噪音,并同时对要恢复的低频数据和标准库的低频数据分别进行注意。第二层注意,我们用要重构的低频数据得到的pre的上下文信息进行信息补充。第三层注意,是我们提出的对比注意,不同于普通的transformer,我们用我们要恢复的数据的特征向量作为Q去匹配标准库中低频负荷的特征向量K,对应的高频数据的特征向量作为V。
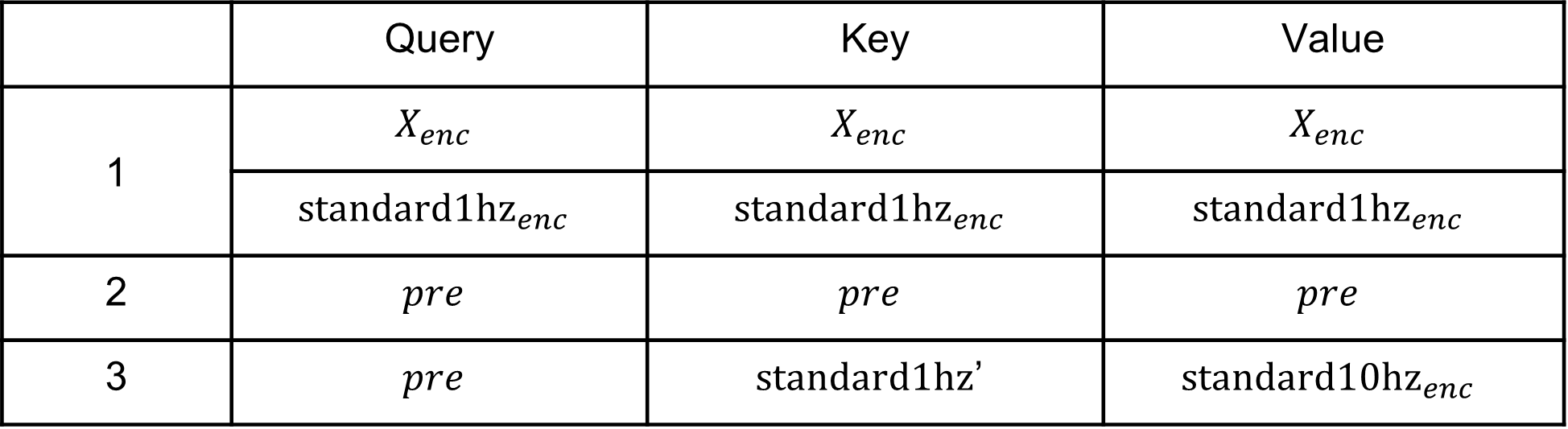
三层注意变量表
4.4 数据重构
最后一个模块是数据重构。在这里我们以10hz数据为例,我们画了时间长度为5秒的离散点。观察负荷数据有一个特点:高频数据每隔5个离散点(即 0.5 秒)规律性变化。根据这个特点我们提出了一种连续周期变异重构策略。例如在1到10的超分辨中,我们先恢复连续的2倍,再恢复周期的5倍变化。连续变化采用MLP实现,周期变化采用亚像素卷积法。
10hz数据的离散表示,时间长度5秒
五、实验结果
我们选取了SRPSED作为数据集,该数据集假设每个负荷点设置1MW的电力供应约200户家庭,参考PLAID并将其放大100倍,模拟900、1000和1250户家庭用电,记为总线5、7和9。实验数据共有60天,我们选取30天作为训练集,19天作为验证集,10天作为测试集,剩下的一天用于构建标准数据库,不做求解的数据。

实验结果
六、可行性分析
在实验中我们使用某一天构建标准数据库,但是对比数据的选取会不会影响结果的稳定性呢?为了回答这个问题,我们在总线7上进行了实验。
我们设置训练集保持不变,但我们将原始验证集(20天)分为两部分,前10天作为待选择的比较数据集,每次只选一天作为标准数据库,后10天作为验证集。结果如表所示,我们在最后一行报告了标准差,结果很稳定。说明我们想法的可行性。
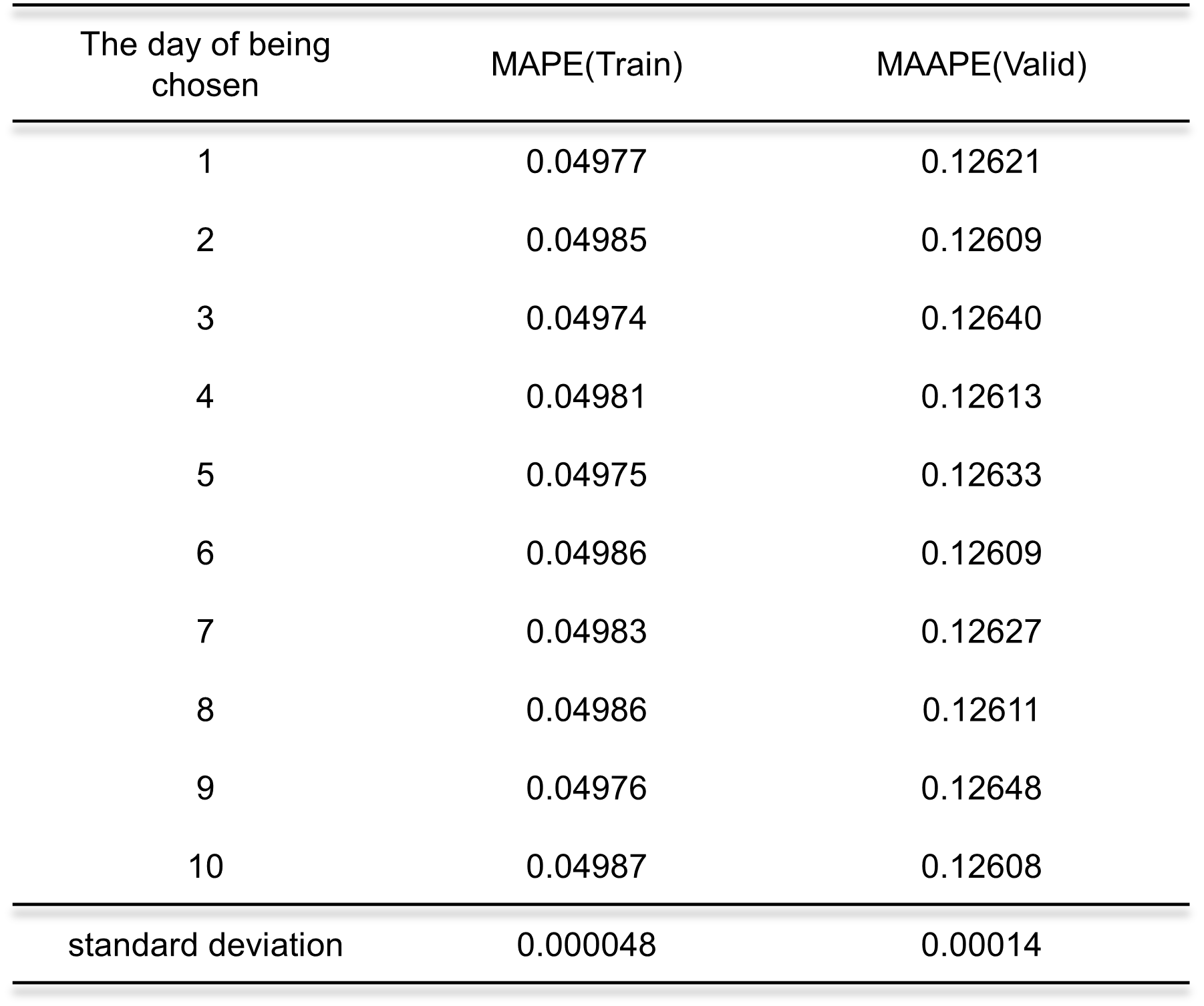
总线7上的稳定性实验结果